NLP: Support Vector Machine
What Is SVM? In machine learning, support-vector machines (SVMs, also support-vector networks[1]) are supervised learning models with associated learning algorithms that analyze data used for classification and regression analysis. Given a set of training examples, each marked as belonging to one or the other of two categories, an SVM training algorithm builds a model that assigns new examples to one category or the other, making it a non-probabilistic binary linear classifier (although methods such as Platt scaling exist to use SVM in a probabilistic classification setting). [Wikipedia]
Train Time: 1.38 seconds
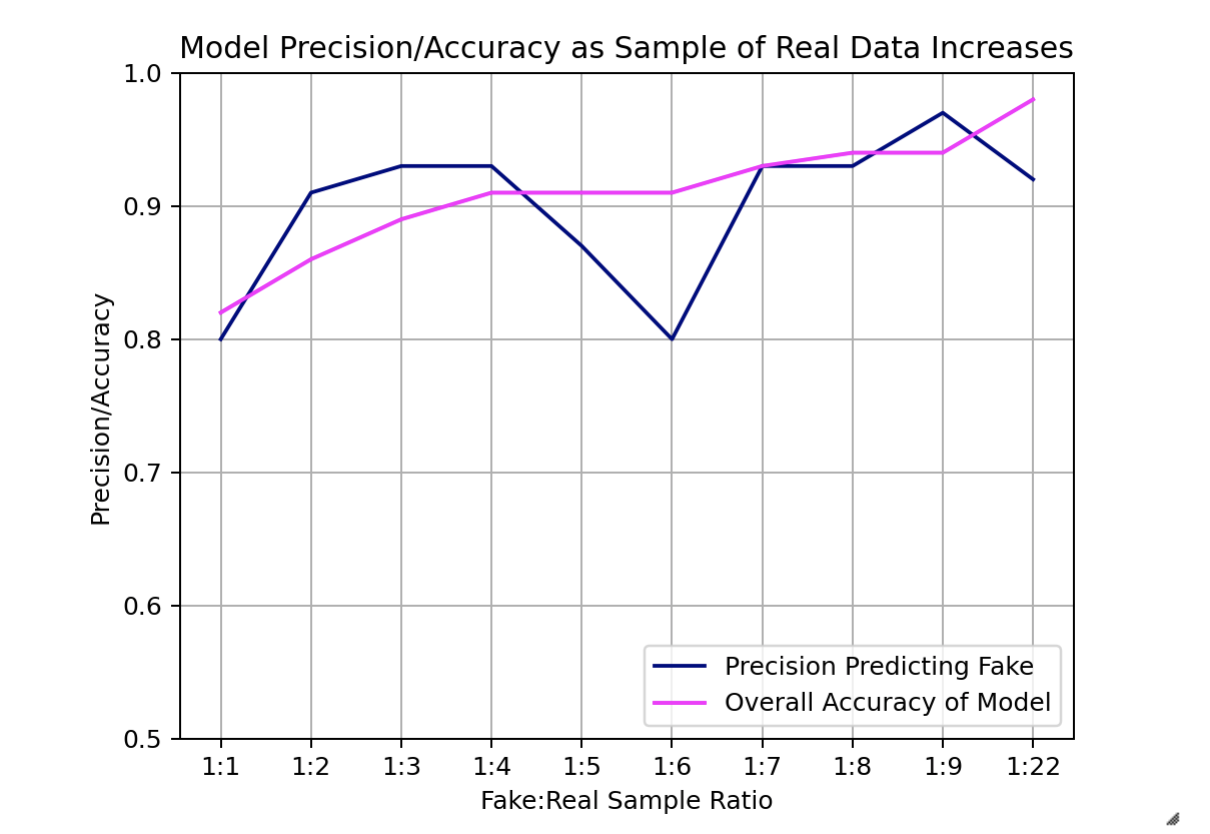
Findings: The Support Vector Machine model ended up being quite an effective and efficient tool for recognizing fraudulent job postings. Prior to any parameter tuning, the model was able to correctly predict a fake job posting 93% of the time, and had an overall accuracy score of .89. After hypertuning and applying the best parameters, the overall accuracy of the model increased slightly to .90, however the model’s precision with regard to fake job postings decreased to .89. We are looking for the model that can correctly pinpoint fraudulent job postings most often. Therefore, we decided to save the model as it was before any tuning of the parameters. We chose a 1:4 sample ratio because after testing a range of sizes for the real data, this ratio allowed for a relatively high precision score for the fraudulent classification without taking a tremendous amount of time. When using ALL of the data available in our dataset, the Support Vector Machine model had a precision score of .92 (lower than with less data) and an overall accuracy of .98 but it took a couple of hours to complete the entire process. The time it took to fit the model to the training data with significantly less real data was 1.26 seconds, and the entire process took only about 5-7 minutes.
Sample Plot: SVM NLP